I’ve been thinking about what I could share from my day job that might be interesting to both actuaries and software engineers. For the software engineers, actuarial science is a mystery, and to most will remain a mystery forever! As a software engineer, I look for ways to abstract away complexity, find patterns, etc. This leads me to the core business problem that I solve for every day—how do we do continuous delivery to actuaries? This generalizes to: how do we deliver regulated financial products to people in an industry sector that manages risk and is risk-averse?
Continuous delivery is “the ability to get changes of all types—including new features, configuration changes, bug fixes and experiments—into production, or into the hands of users, safely and quickly in a sustainable way,” as defined by Jez Humble in 2010.
When sharing ideas, the concepts you care about have outcomes that the business cares about, but often the audience is unable to understand the relationship to the business. Software engineers who are speaking with anyone who’s not a software engineer often forget that their audience doesn’t know anything about software engineering, especially agile and lean concepts. Actuaries are very good at explaining complex concepts to those from other disciplines—because actuaries typically assume their audience requires business context. When describing the benefits of continuous delivery to a risk team, it’s important to focus on the fact that continuous delivery mitigates risk, which is the outcome the risk team cares most about.
There are several examples where the words used are the same between software engineering and actuarial science, but the meanings of those words are very different, which can lead to costly misunderstandings. The misunderstandings are costly because they can take a long time to become apparent. A particularly relevant example is the term "production." In Jez’s definition of continuous delivery, production is used to specify the deployment of a system used by users to derive value. For actuaries, production defines the system used to produce financial results to be consumed by shareholders, regulators, etc. In essence, actuaries follow a process akin to the software development life cycle, where models are built, tested, and signed off, much like software is. To do this, the actuarial team uses a version of the software that engineers call production to develop and test the models. When an engineer tells an actuary to accept continuous delivery into the environment to produce actual financial results, it is obviously unreasonable, but shifting language for either is challenging.
Breaking down the monolith
Continuous delivery can be scary: “You mean to tell me our entire website is going to change several times a day? That’s a bit risky.” Of course, that isn’t the reality. The blast radius on each of those changes is likely quite small, likely can be rolled back, or maybe even a/b tested.
When we spoke to our clients about our wish to provide a software as a service platform, which could change several times a day, built in the cloud (which can also change several times a day)—our clients thought, "That sounds risky…"
When we dug into why it sounds risky, we found that a hugely important feature for our clients was the ability to reproduce financial results and, more critically, control when financial results change so they can provide detailed attributions of why the results changed—this comes from understanding the two definitions of "production." They also care that when they run the system it works and, if it worked yesterday, and didn’t change, it will work today—won’t it? This was the reason why they upgraded our software once a year and why it is “crazy talk” to automatically ship twice a day.
We did have a problem—our product is monolithic in nature (it’s becoming less monolithic). We know the answer is to refactor it to microservices and, in doing so, build a feature that lets our users control what version of our calculation service is used at any given time. It turns out it’s hard to get traction to “refactor our monolithic solution into microservices so we can do continuous delivery” but it is easy to get people excited about the ability to “choose the version of the calculations used when running.” So, we built what is shown in Figure 1.
Figure 1: Edit calculation engine
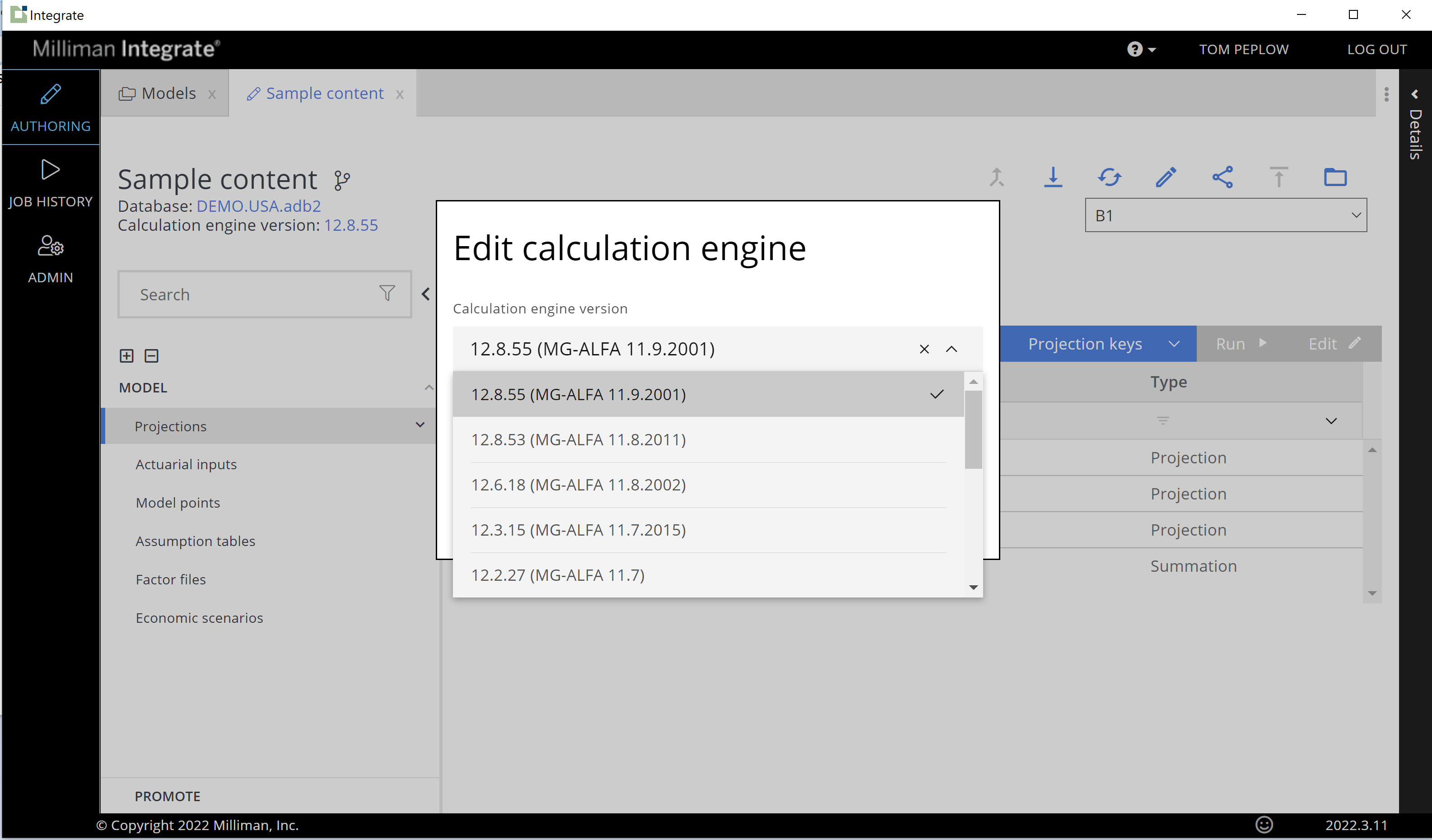
The question, of course, was “why did that take so long? —it’s just a drop-down box!” Well, it didn’t take that long, which is good news, but there is also a tremendous amount of work underpinning this drop-down box that users don’t care about. And you know what? THAT IS OK! Customers aren’t buying your microservices, they are buying the capabilities they provide… And the software engineers reading know how to do this: invert the dependency, define an application programming interface (API), version the API, follow semantic versioning (SemVer) for the API, automate testing so you don’t break compatibility, and… Ship it, a lot, and test in production—you can roll it back… In this case, our users can test new capabilities themselves in production (as defined by a software engineer), but control when that capability is used to produce financial results in production (as defined by an actuary). Abstractly, we support running multiple versions of the same microservice in production (as defined by a software engineer).
What about results changing for reasons you can’t control?
The skeptic reading, and actuaries are pretty good skeptics, would say—you cannot guarantee that results won’t change. In the cloud they are right, but you can try hard. This leads to an interesting question: “What is the calculation service?” Underneath the version number of 12.8.55 is a composition of our execution environment (operating system version, virtual machine type, etc.) as well as our calculation engine executable that does the math(s).
To articulate this, here’s a real-world story: We found that our results changed when we moved to a different virtual machine (VM) type due to the non-associative nature of floating-point arithmetic. This change was a controlled change. We found the difference in a test run of our model. We knew precisely what changed, so we dug in and found that the new architecture of the Gen 4 Haswell processor used FMA3. This caused a difference in the tail of the double precision floating point, but the number was big and thus the change was material (millions of dollars). Thankfully, once we understood this, the impact of the processor architecture, we flipped the _set_FMA_enable(0) switch. This fixed the change in results (at a small performance penalty), and the issue went away. While we did all this investigation, and it was not an insignificant lift, our customers were quite safely using the trusted legacy machines.
This is quite a powerful feature of our product; it has evolved to allow our customers to control some aspects of the virtual machine configuration. This has allowed them to optimize hardware selection to specific models. What this is, to a software engineer, is the value of the cloud, containerization, and infrastructure as code. To our customers it demonstrates a controlled change process that they can use to limit risk.
Putting it together
We are shipping our product a lot more frequently than we were before, and it’s becoming small little microservices and less monolithic. We have a lot of our clients moving to our cloud-based product, and it’s not because we’re in the cloud or have continuous delivery but because we’re solving problems we couldn’t solve before.
I’ve said this before about artificial intelligence (AI). It has promise, but it’s often a solution looking for a problem. Transformation happens by building empathy for the customers and solving their problems. It certainly doesn’t come from one group of people forcing their way of working on another.